成本控制
了解如何在 Everywhere 中更好地管理和优化 Token 消耗,降低使用成本。
在与助手交互的过程中,每一次请求都会消耗 Token,而 Token 的消耗量直接决定了您的 API 使用成本。通过合理的配置与使用习惯,您可以在确保获得高质量回答的同时,显著降低 Token 开销。
本文将为您提供一系列行之有效的 Token 优化策略。
视觉上下文
视觉上下文是 Everywhere 感知和理解屏幕内容的核心机制,但它也是 Token 消耗的大户。对视觉上下文进行精细化配置,是控制成本的首要环节。
在聊天窗口,点击 设置 图标按钮,您可以找到与视觉上下文相关的多个选项:
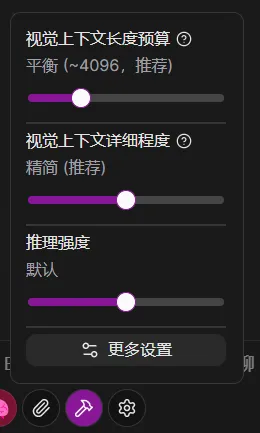
长度预算
- 作用:该设置限制了每次请求中视觉树文本的最大 Token 数量。
- 建议:对于大多数日常任务,保持 平衡 即可。过低的上限可能导致模型无法获取足够的屏幕信息,而过高的上限则会显著增加每次请求的成本。
该设置的数值为估算值,实际发送给模型的视觉树 Token 数量可能会略有不同,具体取决于视觉树内容的复杂度和结构。
详细程度
- 作用:该设置控制了视觉树中元素的描述丰富程度。较高的详细程度会提供更多的上下文信息,但也会增加 Token 消耗。
- 建议:推荐设置为 精简。
自动添加元素
默认情况下,Everywhere 可能会在呼出时自动附带当前焦点的视觉信息。如果您不需要模型感知屏幕内容,可以在主窗口的 聊天设置 中关闭 自动添加元素。

关闭后,仅当您明确需要助手看屏幕时,再在 聊天窗口 中手动添加视觉元素作为附件。对于纯文本交流(如代码编写、翻译、闲聊),这能显著节省不必要的 Token。
提示词
系统提示词 (System Prompt) 是预设给模型的指令,指导其如何理解和执行任务。合理设计和管理提示词是控制 Token 消耗的关键。
Everywhere 默认提供了通用场景的系统提示词,请参阅。
如果您为 自定义助手 配置了自定义系统提示词,请审查其内容。
- 删除重复的指令或不再适用的规则。
- 保持指令简明扼要。过长的提示词不仅增加成本,还可能分散模型的注意力。
并行工具调用
在使用自定义系统提示词时,建议明确允许模型进行 并行工具调用。
并行调用允许模型在单次回复中同时请求执行多个工具,减少了对话轮次,直接避免了因多轮来回交互而导致的上下文重复累积,从而节省 Token。
示例
您可以参考以下提示词片段,引导模型并行工作:
When multiple independent tool calls are needed, you SHOULD make them in parallel instead of sequentially.
会话管理
及时新建对话
随着对话的深入,历史消息会不断累积,导致后续每一次请求的上下文越来越长,Token 消耗也随之增加。
当您结束一个话题并准备开始新任务时,请务必 手动新建对话。
清空上下文不仅能让 Token 计数归零,还能消除旧信息的干扰,帮助模型更精准地聚焦于新任务。
插件与工具
按需启用插件
点击聊天窗口的 工具 图标按钮,管理当前启用的插件。
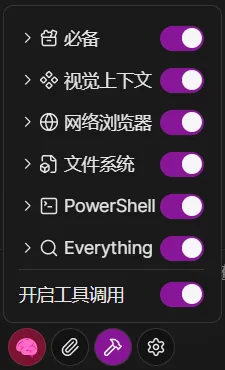
每一个启用的插件,其工具定义(包含名称、描述、参数结构)都会被注入到系统提示词中,增加 Token 消耗。
我们建议您仅开启当前任务必需的插件。例如,在进行文本创作时,关闭与文件操作或网络请求相关的插件;在需要外部数据支持时,再启用相应插件。
纯对话
如果您当前仅进行问答、创意写作或翻译等不需要外部工具的任务,我们建议在聊天窗口直接关闭 工具调用 总开关。
此时,模型将完全不考虑工具调用相关的提示词内容,专注于文本生成,显著降低 Token 消耗。
这篇文档对您有帮助吗?
最后更新于